Beyond Scale: Engineering Compute-Optimal Language Models
1. Beyond Scale – A New Paradigm for LLM Efficiency
Early work by Kaplan et al. (2020)1 revealed power-law relationships between model size, dataset volume, and training compute, suggesting that larger language models deliver more capability per unit of FLOPs. This insight fueled an era of aggressive model scaling under the assumption that “bigger is better.”
But this paradigm was upended by Hoffmann et al. (2022)2 in their Chinchilla study. They showed that, for a fixed compute budget, training a smaller model on substantially more high-quality data yields better performance. For instance, Chinchilla (70 B parameters trained on 1.4 T tokens) outperformed the much larger Gopher (280 B parameters, 300 B tokens)3—despite both models consuming roughly the same number of training FLOPs.
Subsequent analyses, such as Porian et al. (2024)4, reconciled apparent contradictions between early and revised scaling laws by accounting for factors like warm-up schedules, embedding-layer computation, and optimizer hyperparameters. Once normalized, both theories converged on a common insight: compute, not parameter count alone, is the true budget.
This shift in perspective marks a turning point. No longer is raw scale the ultimate goal; instead, the question becomes: how do we make every FLOP count?
The remainder of this post explores the principles and techniques that are driving this shift from “larger” to “smarter.”
2. Bottlenecks in Modern LLM Development
Training a frontier-scale language model now consumes thousands of GPU-days and millions of dollars. Inference remains similarly burdensome: serving a 70 B‑parameter model with real-time latency may require multiple GPUs or specialized accelerators. These escalating costs demand a decisive pivot toward efficiency.
Three deeply interrelated bottlenecks are driving this shift:
- Compute and memory constraints: Autoregressive generation is inherently sequential, limiting token throughput even on the most advanced hardware. Moreover, the sheer scale of modern models necessitates distributed memory systems, introducing significant communication overhead and power consumption.
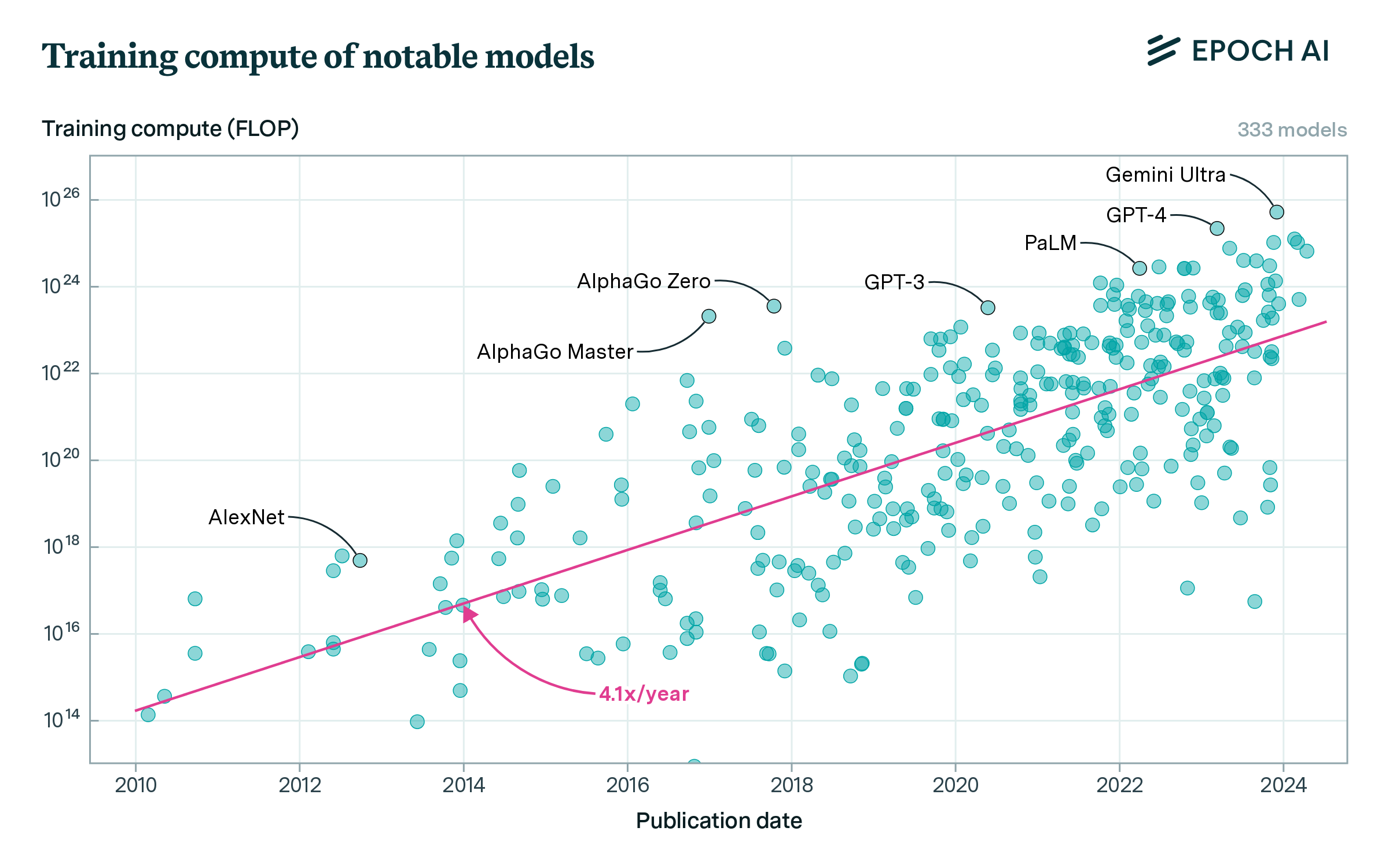
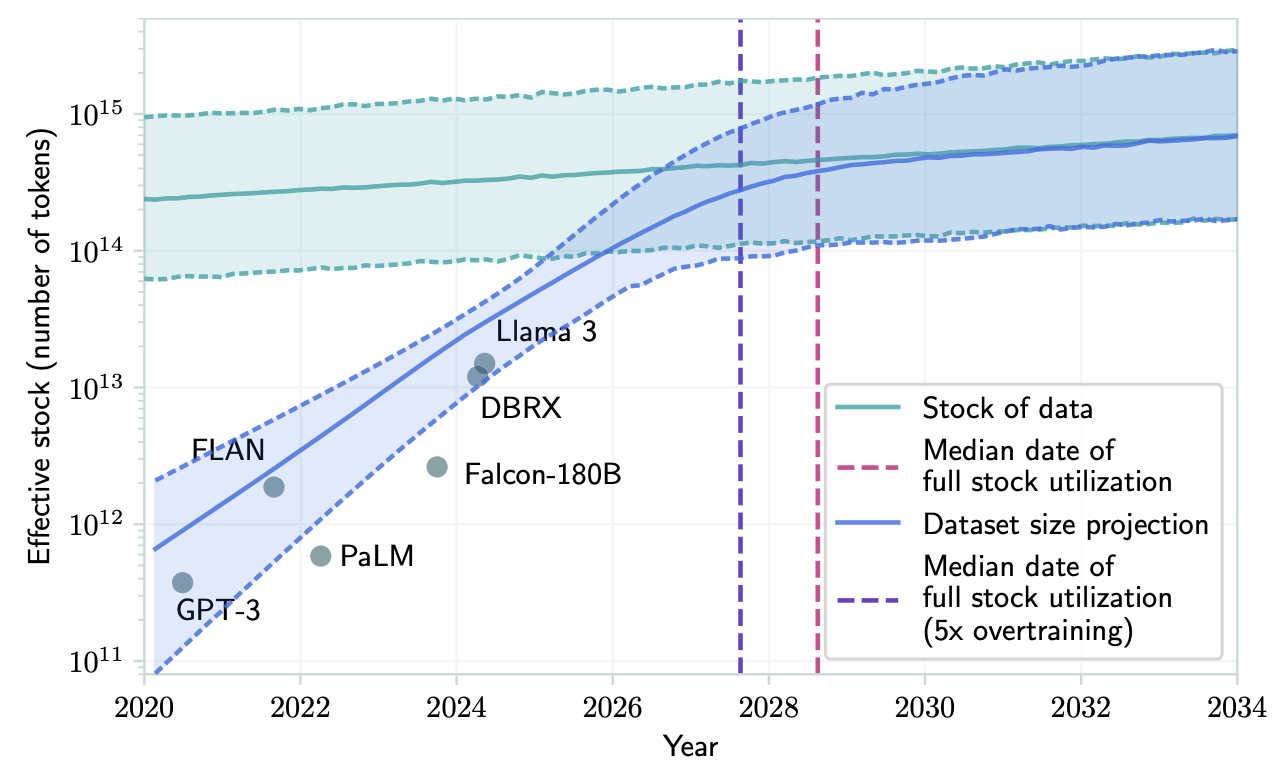
- Data scarcity: By 2025, most high-quality English web text has already been mined. Scaling Chinchilla-style training to models with 500 B parameters or more would require trillions of high-quality tokens—an unattainable volume. As a result, strategies like deduplication, aggressive filtering, and synthetic data augmentation have become indispensable in maintaining data efficiency.
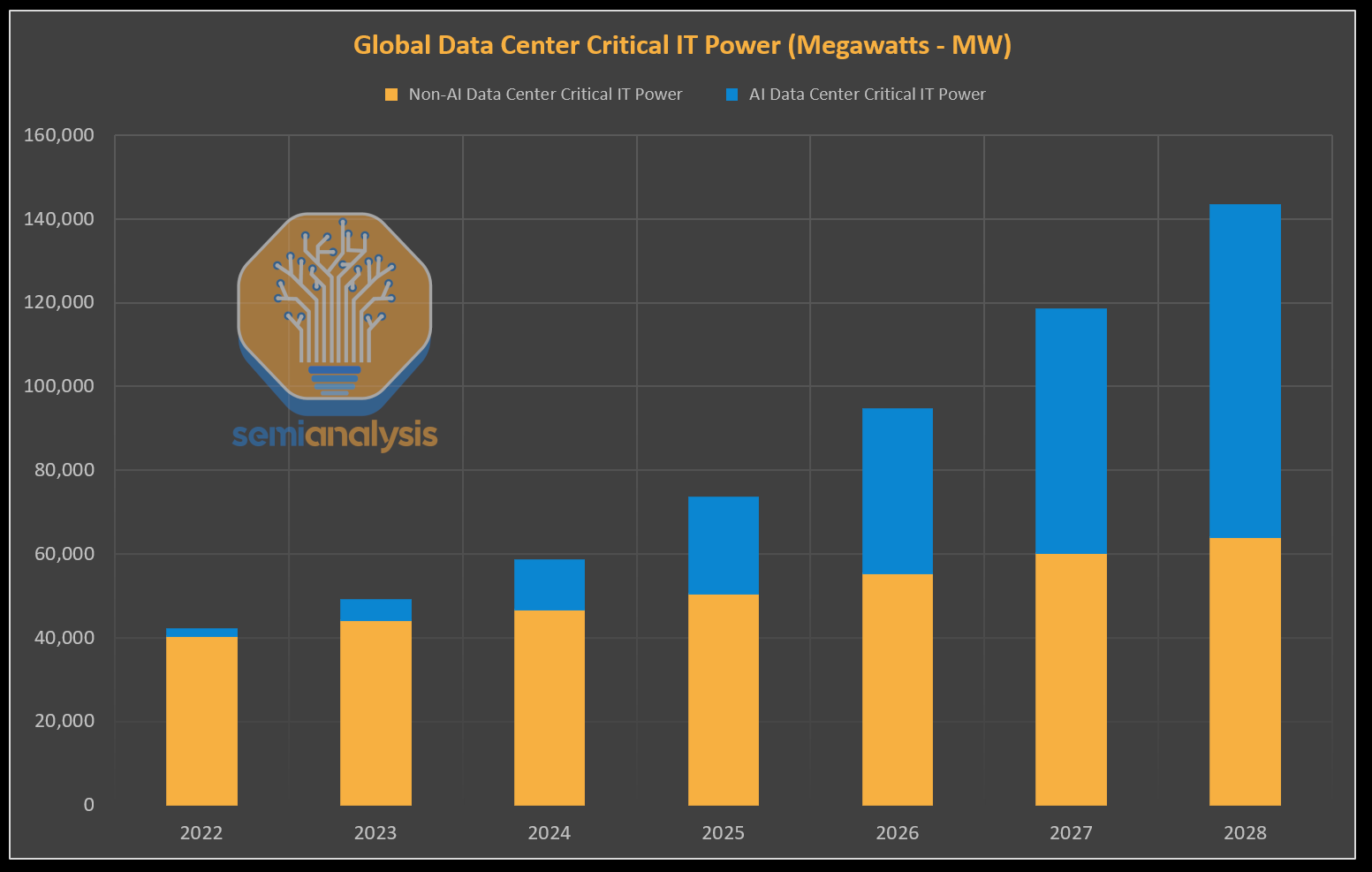
- Environmental impact: In the near future, the power demands of AI data centers are expected to surge as LLM deployment expands, making carbon emissions and environmental sustainability pressing global issues.
These challenges are not isolated—they amplify each other. Compute limitations constrain throughput and model capacity; insufficient data reduces generalization; and both exacerbate energy consumption. Together, they underscore a fundamental shift: efficiency must be engineered into LLMs from the outset—not retrofitted as an afterthought.
3. Core Innovations for Compute-Optimal LLM Design
The pursuit of compute-optimal language models is shaped by two reinforcing pillars:
Refined scaling laws – offering a quantitative blueprint for how error scales with compute when all FLOPs are accounted for properly.
Practical optimization techniques – spanning data curation, precision tuning, sparsity, and system-level algorithms that help real models approach the theoretical optimal frontier.
3.1. Refining the Scaling Laws
Kaplan et al.1 proposed an early scaling formula:
\[N_{\text{opt}} \propto C^{0.73}\]where \(N_{\text{opt}}\) is the optimal number of model parameters, excluding embedding layers, for a given compute budget \(C\). However, this exponent likely overestimates model size requirements due to the omission of embedding-layer parameters and the reliance on limited training data.
Recent analyses converge around a revised exponent of approximately 0.548:
\[N_{\text{opt}} \propto C^{0.5}\]more closely aligning with Chinchilla’s findings.
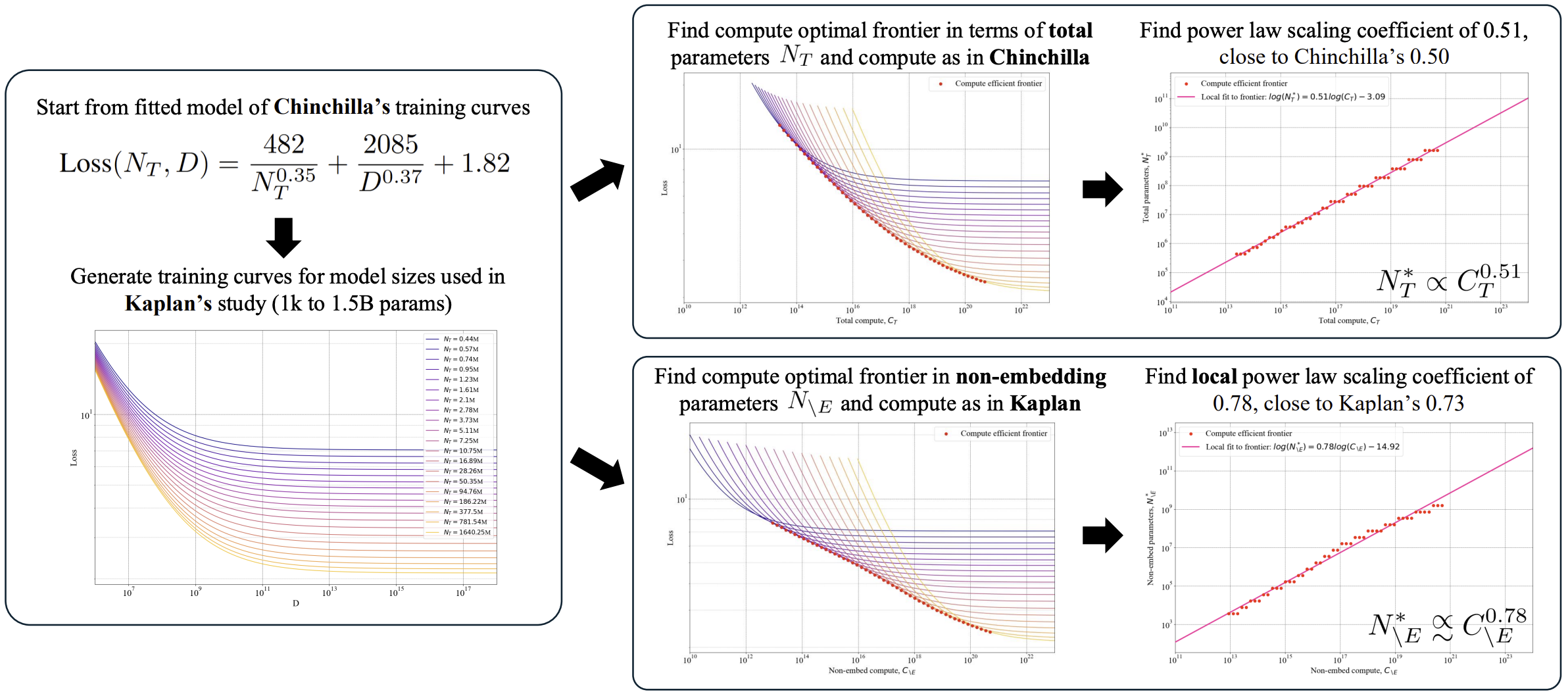
Moreover, numerical format plays a significant role: a recent study9 demonstrates that the optimal scaling behavior differs depending on whether FP32, BF16, or FP8 is used—indicating that numerical precision must be formally integrated into scaling law formulations. This intersection between scaling behavior and numerical representation remains an open and important area of research.
3.2. Practical Efficiency Techniques
Refined scaling laws offer a theoretical blueprint for compute-optimal model design—quantifying how performance scales with compute under idealized assumptions. However, bridging the gap between theory and real-world deployment requires addressing practical dimensions that scaling curves alone cannot capture.
Recent innovations build on this foundation, spanning four key areas that help real models approach the theoretical efficiency frontier:
Data-aware training: Not all data is equal. Studies1011 confirm that carefully curated or re-weighted corpora often outperform naively scaled-up datasets—highlighting that data quality, not just quantity, drives generalization.
Precision-aware scaling: Training in lower-precision formats (e.g., FP8, INT8) reduces memory and bandwidth requirements, enabling deeper or wider networks under the same compute ceiling. Numerical precision, as shown in recent studies9, interacts directly with scaling behavior.
Architectural efficiency: Emerging techniques like Mixture-of-Experts with dynamic routing12 activate only a small subset of model weights per token. Sparse attention mechanisms—such as SparseFlow13 further reduce compute without sacrificing expressivity.
System and algorithmic optimization: Smarter training optimizers like Sophia14 accelerate convergence. System-level techniques, such as advanced parallelism strategies15, minimize overhead and maximize throughput.
Together, these techniques operationalize the principles of compute-optimal design—enabling LLMs that are not just theoretically efficient, but practically deployable at scale.
4. The Forefront of LLM Efficiency: Key Research Directions
Recent efforts toward compute-optimal LLMs span multiple layers—from data to systems. In this section, we introduce recent research efforts that exemplify the push toward efficient LLM design across different layers of the stack.
4.1. Smarter Data Selection
Rather than indiscriminately scaling up datasets, recent work focuses on selecting and weighting training data to maximize return per FLOP. Model-aware curation consistently outperforms brute-force accumulation.
MATES16 dynamically estimates sample influence during training to prioritize impactful data. This method yields over 2× better zero-shot accuracy using only half the compute.
DeepDistill17 filters samples based on response variance and pass rates, constructing difficulty-aware corpora that enhance reasoning performance on tasks like GSM8K—without inflating dataset size.
Ultra-FineWeb18 combines verified filtering with scalable fastText classification to create a 1T-token corpus optimized for diversity and quality at low curation cost.
These approaches show that selective, adaptive training signals can significantly enhance both generalization and efficiency.
4.2. Precision-Aware Training
Precision has emerged as a critical factor in shaping scaling behavior, impacting both performance and resource efficiency.
- Kumar et al.9 systematically analyze how compute–performance tradeoffs vary across FP32, BF16, and FP8. Their findings show that models trained in lower-precision formats can match or exceed FP32 performance at a fraction of the cost, enabling deeper architectures or larger batch sizes under fixed budgets.
These results position numerical precision not merely as a hardware concern, but as a core design axis in compute-optimal planning.
4.3. Efficient Model Architectures
Architecture plays a central role in reducing active computation through conditional execution and sparsity.
Cllms19 enforce consistency across partial sequences to enable iterative parallel decoding, achieving up to 3.4× inference speedup without modifying the model architecture.
HAMburger20 replaces standard per-token decoding with a learned compositional fusion of tokens, enabling dynamic multi-token generation per forward step. This improves hardware efficiency by reducing KV cache growth and activation overhead.
PARD21 transforms autoregressive draft models into efficient parallel predictors via masked-token training, significantly reducing per-token compute cost without altering model weights.
These designs exemplify token-aware specialization and sparse activation, enabling models to allocate compute only where needed.
4.4. Inference-Time System Design
No model is efficient without efficient deployment. Recent work focuses on optimizing runtime systems to support high-throughput, low-latency inference.
- gLLM22 introduces a system-level framework for serving large models with minimal latency. Its Token Throttling mechanism schedules prefill and decode tokens dynamically, based on runtime signals such as KV cache usage and queue depth. In combination with an asynchronous, non-blocking execution model, this approach improves GPU utilization under variable load and delivers up to 3.98× higher throughput compared to conventional stacks.
These system-aware techniques demonstrate that runtime optimization is essential for realizing the full benefits of compute-efficient models.
5. Open Challenges and Future Research Directions
Despite progress, compute-optimal LLMs are still far from solved. Below are five key challenges that require deeper integration of theory, practice, and systems thinking.
Toward Multi-Dimensional Scaling Laws: Current scaling laws focus mainly on parameters and compute. But they ignore curriculum design, optimizer behavior, and numerical precision. A complete theory must model how these factors jointly affect performance.
Cross-Stack Joint Optimization: Pruning, quantization, and data filtering are often tuned separately. But they interact in complex ways. Jointly optimizing the full stack—data, model, system—can yield much greater gains.
Dynamic and Adaptive Inference: Efficient models should scale compute to match task difficulty. Adjusting expert usage, precision, or decoding on demand can save resources without hurting quality. This remains largely unexplored.
Hardware Portability: Many optimizations rely on custom hardware. Making efficient models work well across GPUs, TPUs, and edge devices is still a major engineering hurdle.
Sustainability-Aware Metrics: FLOPs and latency don’t tell the full story. Energy use, carbon cost, and monetary efficiency should be part of standard benchmarks to guide sustainable progress.
6. Conclusion: Towards Compute-Optimal LLMs
The era of “bigger is better” has evolved into an era of efficiency. Scaling laws have matured, data-centric training has outpaced brute-force token accumulation, and precision-aware methods now extract more performance per FLOP than raw parameter growth alone could deliver. Compute-optimality is no longer a theoretical goal—it is fast becoming a practical necessity. Building truly compute-optimal LLMs will require:
Unified design frameworks that explore the high-dimensional efficiency landscape holistically;
Self-adaptive systems that dynamically modulate compute at runtime to meet task-specific constraints; and
Sustainability-aware evaluation standards that align model performance with real-world resource limitations.
Efficiency, once treated as a trade-off, is now the design frontier. The next generation of language models won’t just be larger or faster—they’ll be intelligently engineered, dynamically efficient, and environmentally sustainable. As scale becomes ubiquitous, the differentiator will be how well we use every FLOP—not how many we consume.
References
Kaplan, Jared, et al. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020). ↩︎ ↩︎2
Hoffmann, Jordan, et al. “Training compute-optimal large language models.” arXiv preprint arXiv:2203.15556 (2022). ↩︎
Rae, Jack W., et al. “Scaling language models: Methods, analysis & insights from training gopher.” arXiv preprint arXiv:2112.11446 (2021). ↩︎
Porian, Tomer, et al. “Resolving discrepancies in compute-optimal scaling of language models.” Advances in Neural Information Processing Systems 37 (2024): 100535-100570. ↩︎ ↩︎2
Jaime Sevilla, Epoch AI, Training Compute of Frontier AI Models Grows by 4-5x per Year, https://epoch.ai/blog/training-compute-of-frontier-ai-models-grows-by-4-5x-per-year ↩︎
Villalobos, Pablo, et al. “Position: Will we run out of data? Limits of LLM scaling based on human-generated data.” Forty-first International Conference on Machine Learning. 2024. ↩︎
Dylan Patel, semianalysis, AI Datacenter Energy Dilemma – Race for AI Datacenter Space https://semianalysis.com/2024/03/13/ai-datacenter-energy-dilemma-race/ ↩︎
Pearce, Song. “Reconciling Kaplan and Chinchilla Scaling Laws.” Transactions on Machine Learning Research (2024). ↩︎ ↩︎2
Kumar, Tanishq, et al. “Scaling laws for precision.” arXiv preprint arXiv:2411.04330 (2024), ICLR 2025 Oral. ↩︎ ↩︎2 ↩︎3
Muennighoff, Niklas, et al. “Scaling data-constrained language models.” Advances in Neural Information Processing Systems 36 (2023): 50358-50376. ↩︎
Goyal, Sachin, et al. “Scaling Laws for Data Filtering–Data Curation cannot be Compute Agnostic.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. ↩︎
Huang, Haiyang, et al. “Toward efficient inference for mixture of experts.” Advances in Neural Information Processing Systems 37 (2024): 84033-84059. ↩︎
Kim, Yeachan, and SangKeun Lee. “SparseFlow: Accelerating Transformers by Sparsifying Information Flows.” Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. ↩︎
Liu, Hong, et al. “Sophia: A scalable stochastic second-order optimizer for language model pre-training.” arXiv preprint arXiv:2305.14342 (2023). ↩︎
Bercovich, Akhiad, et al. “FFN Fusion: Rethinking Sequential Computation in Large Language Models.” arXiv preprint arXiv:2503.18908 (2025). ↩︎
Yu, Zichun, Spandan Das, and Chenyan Xiong. “Mates: Model-aware data selection for efficient pretraining with data influence models.” Advances in Neural Information Processing Systems 37 (2024): 108735-108759. ↩︎
Tian, Xiaoyu, et al. “Deepdistill: Enhancing llm reasoning capabilities via large-scale difficulty-graded data training.” arXiv preprint arXiv:2504.17565 (2025). ↩︎
Wang, Yudong, et al. “Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data.” arXiv preprint arXiv:2505.05427 (2025). ↩︎
Kou, Siqi, et al. “Cllms: Consistency large language models.” Forty-first International Conference on Machine Learning. 2024. ↩︎
Liu, Jingyu, et al. “HAMburger: Accelerating LLM Inference via Token Smashing.” arXiv preprint arXiv:2505.20438 (2025). ↩︎
An, Zihao, et al. “PARD: Accelerating LLM Inference with Low-Cost PARallel Draft Model Adaptation.” arXiv preprint arXiv:2504.18583 (2025). ↩︎
Guo, Tianyu, et al. “gLLM: Global Balanced Pipeline Parallelism System for Distributed LLM Serving with Token Throttling.” arXiv preprint arXiv:2504.14775 (2025). ↩︎